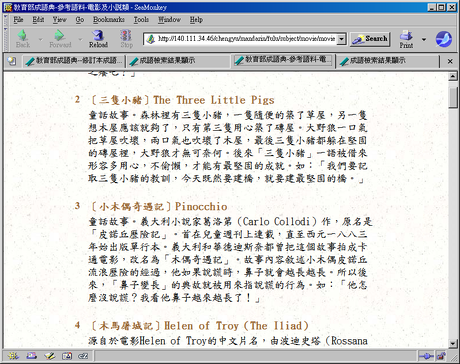
前些天的新聞笑料有一條是教育部將「三隻小豬」一類的童話故事也編入教育部頒成語典,被諸記者們拿出來好好報了一下。這是條放在正式新聞時段的花邊新聞,所以我就在麵店配著麵也笑了一笑。
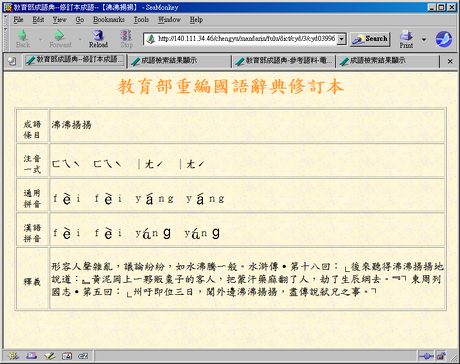
不過,從後續一些材料看來,其實教育部好像沒那麼沒學問。本來嘛,會編字典辭典的學者們,應當都是飽學之士,和我這種沒事上網拿 google 當動詞的人絕對不一樣,怎麼會分不清楚三隻小豬和沸沸揚揚的不同呢?有圖有真相,看到這兩個詞語解釋的人,一定不會覺得它們是同一類的成語:
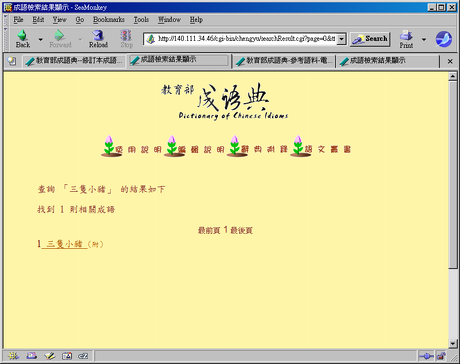
這樣看來完全是記者隨便亂報了嘛。嗯,我們再來看一下進入成語詞條內容之前的查詢結果頁面,這是三隻小豬的:
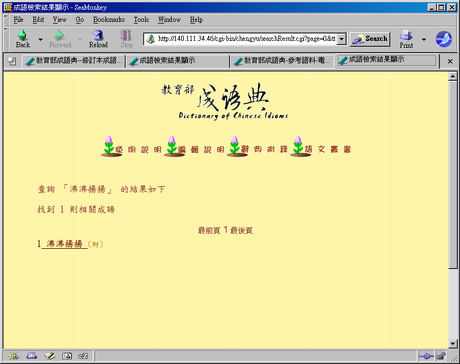
這是沸沸揚揚的:
看起來還真像。如果我不點進去,一定會以為這兩個成語是差不多等級的成語:教育部,這怎麼回事,三隻小豬在沸沸揚揚什麼!
教育部成語典的內容或許沒有問題,這點我無法確認,因為手上沒有這本字典。若身為一個報導人員,看到這種網頁,理應去找出印行的出版品,確認成語典的內容究竟有沒有問題。然而,這個社會上大部分的人家裡沒有學齡兒童,大概不會買一本成語典放著;真有買的家庭,家長大概也沒有時間去讀。新聞的閱聽眾如果想確認這則新聞的真實性,最方便的手段便是上教育部的網站,查網路版成語典。
查網路版成語典,如果一上網就直接查詢,沒有進入成語條目細看的話,很有可能就會認為記者報導為真:沸沸揚揚和三隻小豬的查詢結果差不多嘛,誰知道一個在本文一個在附錄呀!
所以,教育部要作個網路版成語典也不作好,介面難用,查出來的結果還諱莫如深。好好一個成語典連 domain name 也沒有,像樣嗎?被人亂扣帽子也不奇怪呀。
講了這麼多,倒也不是要怪教育部的網站作不好,只是想提點心得:網站作不好是會上新聞的。
補注:看來我查的沸沸揚揚也沒有列入成語典本文。罄竹難書才有。不過網站介面作得爛這一點,不會因為我的錯誤而改變。
google.de 的域名也會被搶掉耶,這些域名蟑螂真的很厲害。前一陣子 seety.net 到期,我盯著 Jan. 11, 2007 的到期日,試了好久都註冊不下來。過了一兩天就看到域名被 renew 了。這檔子兒事還是需要一些專業知識和技術的呢。
不過,google.de 現在看起來是已經正常了。
django.contrib.admin 是 Django 框架裡實作 CRUD 的重要元件。這個 admin 是一個獨立的 Django app,它允許對所有 Django 所支援的資料模型進行操作。因為它的功能強大,所以許多人希望為它延伸功能,好和自己寫的 app 結合在一起,相得益彰;最好是能夠無縫結合,那就太完美了。
卡難啦!Django admin CRUD 樣樣都行,還加上認證和權限管理,真要作到無縫結合,大概也會把 admin 的程式碼全翻過一遍了;這樣一搞,說不定也不必花多少力氣就能改出自己版本的 admin。而且 admin 的設計主要是針對 webmaster/superuser,雖然配有權限系統,但是該權限系統乃是 table-specific 而非 row-specific。也就是說,像本站這種 multi-user 系統,得要另外考慮權限的實作,不能使用內建的系統,使得無法將 admin 介面提供給終端使用者來使用。
其實稍微複雜一點的網頁程式系統大概就會是這種狀況。Django admin 還是很不錯的工具,但程式設計員不能在後台系統上偷懶。尤其現在網頁程式的設計趨勢是靠 ajax 把部分後台的功能作到前台,想要全靠 admin 提供後台管理功能也是有點不太實際的。
從 limodou 的 [Django动态]newforms Admin分支开始了 也可以看到類似的想法。newforms 是 Django 邁向 1.0 的重要元件之一,以 newforms 重構 admin 或許是必然的一個步驟。然而,我想 admin 要從 webmaster 管理工具,改變成終端使用者工具的機會應該不大。畢竟即使在 newforms admin 的 "Would be nice, and we're going to try our hardest to get this in" goals 裡,至多也只有 "Give developers extra hooks" 這一項。
如果 Django 要有高度自訂的後台管理程式庫,可能不會以舊 admin 或 newforms admin 的形式出現吧。
Posted by yungyuc
at
22:04,
0 comment,
0 trackback.
Trackback SPAM 是很討厭的東西;它不像 comment SPAM 可以用 captcha 或帳號/密碼來擋。Trackback 都是由 blog 軟體系統發出來的資料,所以要擋可以,必須考慮到這中間缺乏使用者的互動,否則就會連正常的 trackback 也擋掉。
感謝 Mark 的許多指教,讓我知道處理 trackback SPAM 常用的幾種方法:
- 不良的行為。
- DNSBL.
- 內容驗證。
我處理 trackback SPAM 的經驗還不夠,無法歸納出 trackback 中的「不良的行為」。因此,我往 2, 3 兩種方法裡面去進行。DNSBL 是許多郵件主機 (或客戶端程式) 用來判別的方式,不過不知道是不是我的處理方式有問題,所有進我這邊的 trackback SPAM 來源都不在這些 DNSBL 裡面。
DNSBL 無法擋掉進來的 trackback SPAM,所以就得實作內容驗證的程式了。幸好,這對 Python 來說是小菜一碟,利用 urllib2,不到二十行就解決了。內容驗證的要訣,根據 Mark 提供的原則,是去 trackback 來源的 URL 把 HTML 內容抓回來,在其中搜尋是否有我這個 blog entry 的 URL。這個原則很合理。一般會 trackback 我的人,在 blog 的內容裡面多半都會提到我的 entry (不然他為什麼要 trackback 呢),也通常會附上 entry URL。
目前內容驗證是這裡 anti-trackback-spam 的主力。為了要通過此處的 trackback 內容驗證,希望對此處 entry 進行 trackback 的朋友們,必須在寫完你的 blog,儲存好可以給別人看之後,再進行 trackback 動作。否則,trackback 內容驗證程式抓不到你的 blog 內容,自然會把你的 trackback 當成 SPAM 囉。
Posted by yungyuc
at
17:09,
0 comment,
0 trackback.
Posted by yungyuc
at
20:54,
0 comment,
0 trackback.
對,我開始改這裡的程式了。所以紀錄一下編網頁的時候會用到的 autocmd:
au BufRead *.py set ai et nu sw=4 ts=4 tw=79
au BufRead *.html set ai et nu ts=4 sw=4
au BufRead *.htm set ai et nu ts=4 sw=4
au BufRead *.css set ai et nu ts=4 sw=4
再補一個 reStructuredText 的:
au BufRead *.rst set ai et nu ts=2 sw=2
Posted by yungyuc
at
18:11,
0 comment,
0 trackback.
得 mee 的推薦而購入此書 (豆瓣紀錄),今日一舉讀完,感覺暢快無比。本書雖然講得是翻譯,但其內容對於今日任何寫稿人而言,都有極大的幫助;中文已經西化甚至日化得十分嚴重,下筆時不仔細推敲,寫出來的東西太容易「不成話」了。
這本書讀一遍是不夠的。當置於架上趁手處,時時翻閱以得提醒。其中「代名詞」、「中文修詞」、「英文字」、「毛病」、「中國的中文」幾篇所舉的例子非常實際,特別有用。
Posted by yungyuc
at
23:04,
0 comment,
0 trackback.
Jacob Kaplan-Moss 在 Django-developer 上發了一篇長文:「往 1.0 前進」。文章是三天前發的,裡面寫有 Jacob 對 1.0 該包含哪些東西,以及他自己的 roadmap。
Posted by yungyuc
at
19:42,
0 comment,
0 trackback.
把 Python 分類到 dynamic language,看起來就比 scripting language 專業!
thegiive 真的很知道玩 dynamic language (這個名詞聽起來就比 scripting language 厲害多了吧) programming 的人對什麼會感冒:
光是「絕對不是 JavaScript 那種 SCRIPT 語言可以比較的!」這句話,就會被 PHP / Perl / Python 社群罵死,根本不用 Ruby 來補這一刀。
所以我就忍不住也想要來淌一下混水了 (雖然不想罵死誰) ... 很久很久很久沒這樣幹了呀 :D 從奇怪的角度來看,對我個人來講,這也算是個紀念 :p
» continue reading
看到 Thinker 的「奇計淫巧」,便想對 Python 的 boolean expression 與 conditional expression 作點探討與整理。
» continue reading
Posted by yungyuc
at
21:32,
0 comment,
0 trackback.